A few days ago, one of my clients ran into an issue: the CI pipeline for the develop branch suddenly stopped working. Strangely enough, pipelines for other branches — feature, hotfix — were running just fine. The situation seemed odd.
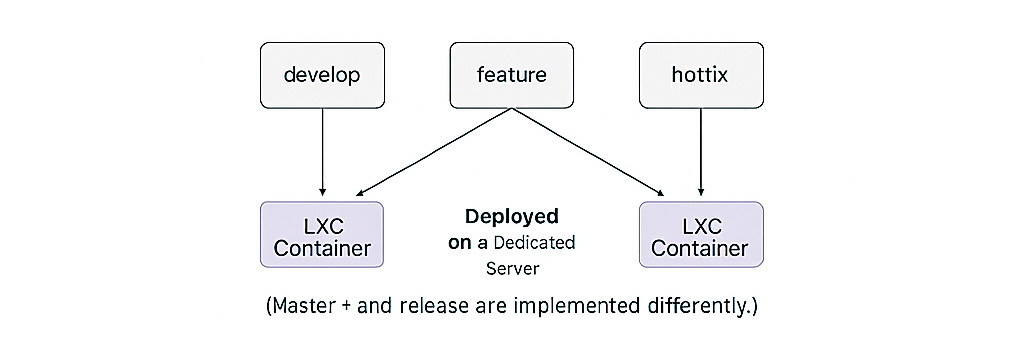
The project setup is such that each branch (develop, feature, hotfix) is deployed on a separate dedicated server inside LXC containers. (master and release are handled differently.) Everything is self-contained. And yet, only the develop branch pipeline stopped triggering.
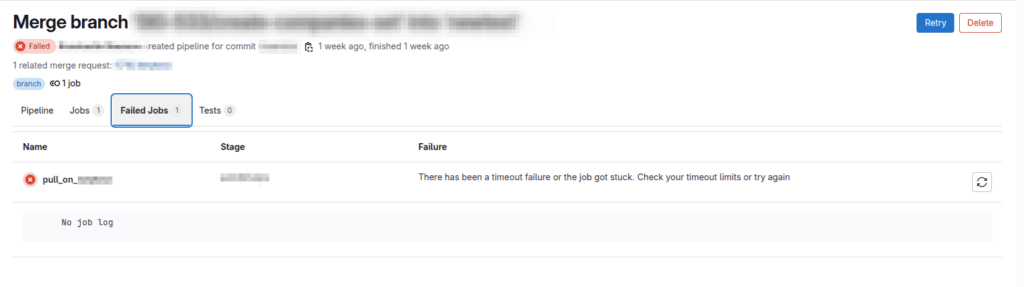
The first thing I did was check the GitLab pipeline status. Either it was marked as “stuck,” or it timed out. The server, containers, and host machine were all functioning normally. So I checked the GitLab Runner inside the container — turns out it couldn’t reach GitLab. That gave me a clue.

I started thinking: what could’ve changed? There had been no major updates or migrations in the last month. But then I remembered — not long ago, I added another virtual bridge (network interface) for a separate container. Everything worked fine at the time, so I forgot about it. But now this new issue popped up with the develop container. Could it be related?
Okay, time to check network connectivity inside the develop container:ping 8.8.8.8 — nothing. No internet.
Checked the host — all good.
Could it be the firewall? Nope.
Pinged another container — it responded fine.
So now it’s 99% likely that the issue is with routing, NAT, or DNS inside the LXD container. Let’s see what’s going on with NAT:
> iptables -t nat -L -n -vNothing. No MASQUERADE rule. Bingo!
Adding the new bridge must have cleared out the NAT rules. As a result, traffic from the develop container wasn’t being masked and couldn’t reach the internet. Without internet, GitLab Runner couldn’t talk to the Git server — and the pipeline never triggered.
I tried restoring the rules manually:
> lxc exec <container-name> -- systemctl restart systemd-networkd— didn’t help.
Restarting the container — nothing.
Tried a few other tricks — still no luck.
I even considered creating a new bridge, but before going that far, I decided to try the simplest thing: just reattach the bridge to the container.
> lxc network detach <bridge-name> <container-name> <interface-name>
> lxc network attach <bridge-name> <container-name> <interface-name>It worked. The container regained internet access.
I ran a runner verification:
> gitlab-runner verifyGitLab Runner happily reported a successful connection, and the pipelines started running again.


The whole thing took about an hour. The hardest part wasn’t technical — it was diagnosing where to start, what to check, and how to connect the dots. In the end, the fix was almost laughably simple: “reconnect.”
It reminded me of an old rule I learned back in the day when I worked in tech support for a telecom company. When a customer would call in saying “Nothing works, everything’s broken,” we had a golden first response: “Did you try turning it off and on again?”
And honestly? That solved the issue in about 40% of cases. Just like this time.